
 Just-in-time (JIT in PostgreSQL) compilation of SQL statements is one of the highlighted features in PostgreSQL 11. There is great excitement in the community because of the many claims of up to a 30% jump in performance. Not all queries and workloads get the benefit of JIT compilation. So you may want to test your workload against this new feature.
Just-in-time (JIT in PostgreSQL) compilation of SQL statements is one of the highlighted features in PostgreSQL 11. There is great excitement in the community because of the many claims of up to a 30% jump in performance. Not all queries and workloads get the benefit of JIT compilation. So you may want to test your workload against this new feature.
However, It is important to have a general understanding of what it does and where we can expect the performance gains. Installing PostgreSQL 11 with the new JIT compilation feature requires few extra steps and packages. Taking the time and effort to figure out how to do this shouldn’t be a reason to shy away from trying these cutting-edge features and testing a workload against the JIT feature. This blog post is for those who want to try it.
What is JIT and What it does in PostgreSQL
Normal SQL execution in any DBMS software is similar to what an interpreted language does to the source code. No machine code gets generated out of your SQL statement. But we all know that how dramatic the performance gains can be from a JIT compilation and execution of the machine code it generates. We saw the magic Google V8 engine did to JavaScript language. The quest for doing a similar thing with SQL statement was there for quite some time. But it is a challenging task.
It is challenging because we don’t have the source code (SQL statement) ready within the PostgreSQL server. The source code that needs to undergo JIT need to come from client connections and there could be expressions/functions with a different number of arguments, and it may be dealing with tables of different number and type of columns.
Generally, a computer program won’t get modified at this level while it is running, so branching-predictions are possible. The unpredictability and dynamic nature of SQL statements coming from client connections and hitting the database from time-to-time give no scope for doing advance prediction or compilation in advance. That means the JIT compiler should kick in every time the database gets an SQL statement. For this reason, PostgreSQL needs the help of compiler infrastructure like LLVM continuously available behind. Even though there were a couple of other options, the main developer of this feature (Andres Freund) had a strong reason why LLVM was the right choice.
. In PostgreSQL 11, the JIT feature currently does:
- Accelerating expression evaluation: Expressions in WHERE clauses, target lists, aggregates and projections
- Tuple deforming: Converting on-disk image to corresponding memory representation.
- In-lining: bodies of small custom functions, operators and user-defined data types are inline-ed into the expressions using them
- You can use compiler optimizations provided by LLVM for preparing optimized machine code.
In this blog, we are going to see how to install PostgreSQL with JIT. Just like regular PostgreSQL installations, we have two options:
- Get PostgreSQL from the packages in the PGDG repository
- Build PostgreSQL from source
Option 1. Install from PGDG repository.
Compiling from source requires us to install all compilers and tools. We might want to avoid this for various reasons. Installing packages from a PGDG repository is straightforward. On production systems or a container, you might want to install only the bare minimum required packages. Additional packages you don’t really use are always a security concern. Distributions like Ubuntu provide more recent versions of libraries and tool-sets in their default repos. However, distributions like CentOS / RHEL are quite conservative — their priority is stability and proven servers rather than cutting-edge features. So In this section of the post is mostly relevant for CentOS7/RHEL 7.
Here are the steps for the bare minimum installation of PostgreSQL with JIT feature on CentOS7
Step 1. Install PGDG repo and Install PostgreSQL server package.
This is usually the bare minimum installation if we don’t need the JIT feature.
sudo yum install https://download.postgresql.org/pub/repos/yum/11/redhat/rhel-7-x86_64/pgdg-centos11-11-2.noarch.rpm sudo yum install postgresql11-server
At this stage, we can initialize the data directory and start the service if we don’t need JIT:
sudo /usr/pgsql-11/bin/postgresql*-setup initdb sudo systemctl start postgresql-11
Step 2. Install EPEL repository
sudo yum install epel-release
Step 3. Install package for PostgreSQL with llvmjit
sudo yum install postgresql11-llvmjit
Since we have already added the EPEL repository, now the dependancy can be resolved by YUM and it can pull and install the necessary package from EPEL. Installation message contains the necessary packages.
... Installing: postgresql11-llvmjit x86_64 11.1-1PGDG.rhel7 pgdg11 9.0 M Installing for dependencies: llvm5.0 x86_64 5.0.1-7.el7 epel 2.6 M llvm5.0-libs x86_64 5.0.1-7.el7 epel 13 M ...
As we can see, there are two packages: llvm5.0 and llvm5.0-libs get installed.
Note for Ubuntu users:
As we already mentioned, Repositories of recent versions of Ubuntu contains recent versions of LLVM libraries. For example, Ubuntu 16.04 LTS repo contains libllvm6.0 by default. Moreover, PostgreSQL server package is not divided to have a separate package for jit related files. So default installation of PostgreSQL 11 can get you JIT feature also.
wget --quiet -O - https://www.postgresql.org/media/keys/ACCC4CF8.asc | sudo apt-key add - sudo sh -c 'echo "deb http://apt.postgresql.org/pub/repos/apt/ $(lsb_release -cs)-pgdg main" > /etc/apt/sources.list.d/pgdg.list' sudo apt install postgresql-11
Option 2. Building from Source
The primary means of distributing PostgreSQL is the source code. Building a minimal PostgreSQL instance requires just a C compiler. But building JIT options requires a few more things. One of the challenges you can run into is different errors during the build process due to older versions of LLVM and Clang present in the system.
Step 1. Download PostgreSQL source tarball and unpack
Tarballs are available in the repository. We can grab and unpack the latest:
curl -LO https://ftp.postgresql.org/pub/source/v11.0/postgresql-11.0.tar.bz2 tar -xvf postgresql-11.0.tar.bz2
Step 2. Get SCL Repository and Install toolset
Latest versions of LLVM, CLang and GCC are available in SCL. We can get everything in a stretch:
sudo yum install centos-release-scl sudo yum install llvm-toolset-7 llvm-toolset-7-llvm-devel.x86_64
Now either you can set or edit your PATH to have all new tools in PATH. I would prefer to put that into my profile file:
PATH=/opt/rh/devtoolset-7/root/usr/bin/:/opt/rh/llvm-toolset-7/root/usr/bin/:$PATH
Alternatively, we can open a shell with SCL enabled:
scl enable devtoolset-7 llvm-toolset-7 bash
We should attempt to compile the source from a shell with all these paths set.
Step 3. Install Additional libraries/tools
Based on the configuration options you want, this list may change. Consider this as a sample for demonstration purposes:
sudo yum install readline-devel zlib-devel libxml2-devel openssl-devel
Step 4. Configure with –with-llvm option and make
Now we should be able to configure and make with our preferred options. The JIT feature will be available if the
--with-llvm
option is specified. For this demonstration, I am using an installation directory with my home (/home/postgres/pg11):
./configure --prefix=/home/postgres/pg11 --with-openssl --with-libxml --with-zlib --with-llvm make make install
Enabling JIT
You may observe that there is a new directory under the PostgreSQL’s lib folder with name
bit code
Which contains lots of files with .bc extension these are pre-generated bytecodes for LLVM for facilitating features like in-lining.
By default, the JIT feature is disabled in PostgreSQL 11. If you want to test it, you may have to enable the parameter
jit
:
postgres=# ALTER SYSTEM SET jit=on; ALTER SYSTEM postgres=# select pg_reload_conf(); pg_reload_conf ---------------- t (1 row) postgres=# show jit; jit ----- on (1 row)
By default, most of the simple queries won’t use JIT because of the cost. The cost is high when JIT kicks in. In case we want to test if JIT is properly configured, we can lie to PostgreSQL that that cost is very low by adjusting the parameter value. However, we should keep in mind that we are accepting negative performance gains. Let me show a quick example:
postgres=# SET jit_above_cost=5;
SET
postgres=# create table t1 (id int);
CREATE TABLE
postgres=# insert into t1 (SELECT (random()*100)::int FROM generate_series(1,800000) as g);
INSERT 0 800000
postgres=# analyze t1;
ANALYZE
postgres=# explain select sum(id) from t1;
QUERY PLAN
-------------------------------------------------------------------------------------
Finalize Aggregate (cost=8706.88..8706.89 rows=1 width=8)
-> Gather (cost=8706.67..8706.88 rows=2 width=8)
Workers Planned: 2
-> Partial Aggregate (cost=7706.67..7706.68 rows=1 width=8)
-> Parallel Seq Scan on t1 (cost=0.00..6873.33 rows=333333 width=4)
JIT:
Functions: 6
Options: Inlining false, Optimization false, Expressions true, Deforming true
(8 rows)
As we can see in the above example, a separate JIT section comes up in the explain plan.
We expect JIT compilation to make a difference in complex analytical queries because the overhead in JIT compilation gets compensated only if the code runs for the duration. Here is a simple aggregate query for demonstration. (I know this is not a complex query, and not the perfect example for demonstrating JIT feature):
postgres=# EXPLAIN ANALYZE SELECT COMPANY_ID,
SUM(SHARES) TOT_SHARES,
SUM(SHARES* RATE) TOT_INVEST,
MIN(SHARES* RATE) MIN_TRADE,
MAX(SHARES* RATE) MAX_TRADE,
SUM(SHARES* RATE * 0.002) BROKERAGE
FROM TRADING
GROUP BY COMPANY_ID;
QUERY PLAN
---------------------------------------------------------------------------------------------------------------------------------------------------------
Finalize GroupAggregate (cost=757298.72..758741.91 rows=5005 width=138) (actual time=16992.290..17011.395 rows=5000 loops=1)
Group Key: company_id
-> Gather Merge (cost=757298.72..758466.64 rows=10010 width=138) (actual time=16992.270..16996.919 rows=15000 loops=1)
Workers Planned: 2
Workers Launched: 2
-> Sort (cost=756298.70..756311.21 rows=5005 width=138) (actual time=16983.900..16984.356 rows=5000 loops=3)
Sort Key: company_id
Sort Method: quicksort Memory: 1521kB
Worker 0: Sort Method: quicksort Memory: 1521kB
Worker 1: Sort Method: quicksort Memory: 1521kB
-> Partial HashAggregate (cost=755916.09..755991.16 rows=5005 width=138) (actual time=16975.997..16981.354 rows=5000 loops=3)
Group Key: company_id
-> Parallel Seq Scan on trading (cost=0.00..287163.65 rows=12500065 width=12) (actual time=0.032..1075.833 rows=10000000 loops=3)
Planning Time: 0.073 ms
Execution Time: 17013.116 ms
(15 rows)
We can switch on the JIT parameter at the session level and retry the same query:
postgres=# SET JIT=ON;
SET
postgres=# EXPLAIN ANALYZE SELECT COMPANY_ID,
SUM(SHARES) TOT_SHARES,
SUM(SHARES* RATE) TOT_INVEST,
MIN(SHARES* RATE) MIN_TRADE,
MAX(SHARES* RATE) MAX_TRADE,
SUM(SHARES* RATE * 0.002) BROKERAGE
FROM TRADING
GROUP BY COMPANY_ID;
QUERY PLAN
---------------------------------------------------------------------------------------------------------------------------------------------------------
Finalize GroupAggregate (cost=757298.72..758741.91 rows=5005 width=138) (actual time=15672.809..15690.901 rows=5000 loops=1)
Group Key: company_id
-> Gather Merge (cost=757298.72..758466.64 rows=10010 width=138) (actual time=15672.781..15678.736 rows=15000 loops=1)
Workers Planned: 2
Workers Launched: 2
-> Sort (cost=756298.70..756311.21 rows=5005 width=138) (actual time=15661.144..15661.638 rows=5000 loops=3)
Sort Key: company_id
Sort Method: quicksort Memory: 1521kB
Worker 0: Sort Method: quicksort Memory: 1521kB
Worker 1: Sort Method: quicksort Memory: 1521kB
-> Partial HashAggregate (cost=755916.09..755991.16 rows=5005 width=138) (actual time=15653.390..15658.581 rows=5000 loops=3)
Group Key: company_id
-> Parallel Seq Scan on trading (cost=0.00..287163.65 rows=12500065 width=12) (actual time=0.039..1084.820 rows=10000000 loops=3)
Planning Time: 0.072 ms
JIT:
Functions: 28
Options: Inlining true, Optimization true, Expressions true, Deforming true
Timing: Generation 5.844 ms, Inlining 137.226 ms, Optimization 201.152 ms, Emission 125.022 ms, Total 469.244 ms
Execution Time: 15696.092 ms
(19 rows)
Here we see a 7.7% improvement in performance. I executed this several times and found that the performance gain is consistently 7-8% for this simple query (which takes 15 seconds to execute). The gains are higher for queries with more calculations/expressions.
Summary
It is fairly simple to install and configure JIT with PostgreSQL as demonstrated above. One point we would like to highlight is that installing JIT packages and enabling the JIT feature can be done online while the database is up and running. This is because all JIT related parameters are dynamic in nature. Parameter changes can be loaded a SIGHUP signal or
SELECT pg_reload_conf()
by the superuser. If it is not helping our workload, we can turn it off anytime. Nothing stops you from trying it in a non-production environment. We might not see a gain in small and simple queries that take less time for execution because the overhead in doing the JIT compilation can become more than executing the SQL statement. But we should expect a good gain in OLAP workload with complex queries that run for a longer duration.



 Please join Percona’s Architect, Tibi Köröcz as he presents
Please join Percona’s Architect, Tibi Köröcz as he presents 

 Please join Percona’s Architect, Tibi Köröcz as he presents
Please join Percona’s Architect, Tibi Köröcz as he presents








 Alexander joined Percona in 2013. Alexander worked with MySQL since 2000 as DBA and Application Developer. Before joining Percona he was doing MySQL consulting as a principal consultant for over 7 years (started with MySQL AB in 2006, then Sun Microsystems and then Oracle). He helped many customers design large, scalable and highly available MySQL systems and optimize MySQL performance. Alexander also helped customers design Big Data stores with Apache Hadoop and related technologies.
Alexander joined Percona in 2013. Alexander worked with MySQL since 2000 as DBA and Application Developer. Before joining Percona he was doing MySQL consulting as a principal consultant for over 7 years (started with MySQL AB in 2006, then Sun Microsystems and then Oracle). He helped many customers design large, scalable and highly available MySQL systems and optimize MySQL performance. Alexander also helped customers design Big Data stores with Apache Hadoop and related technologies.






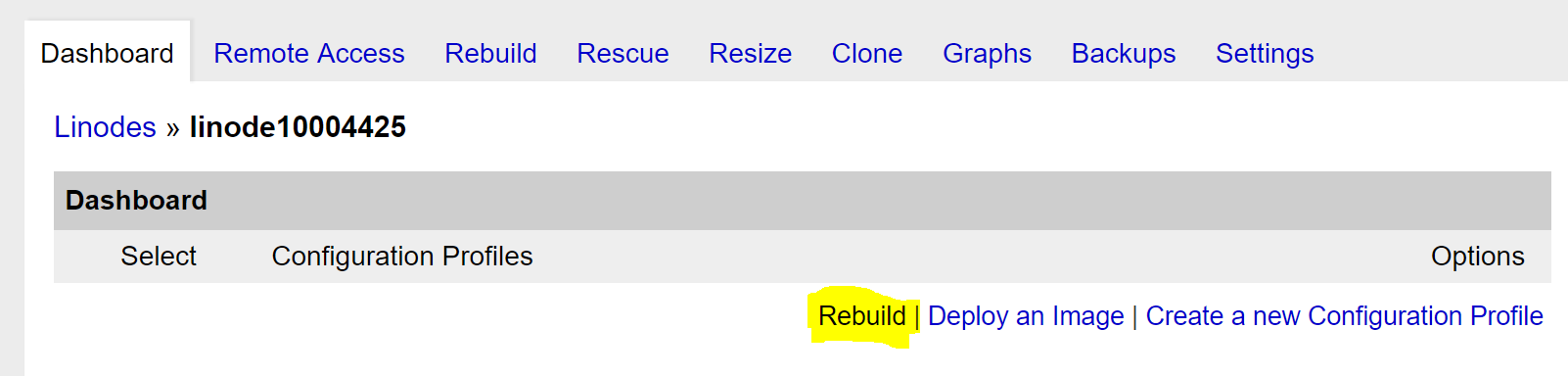
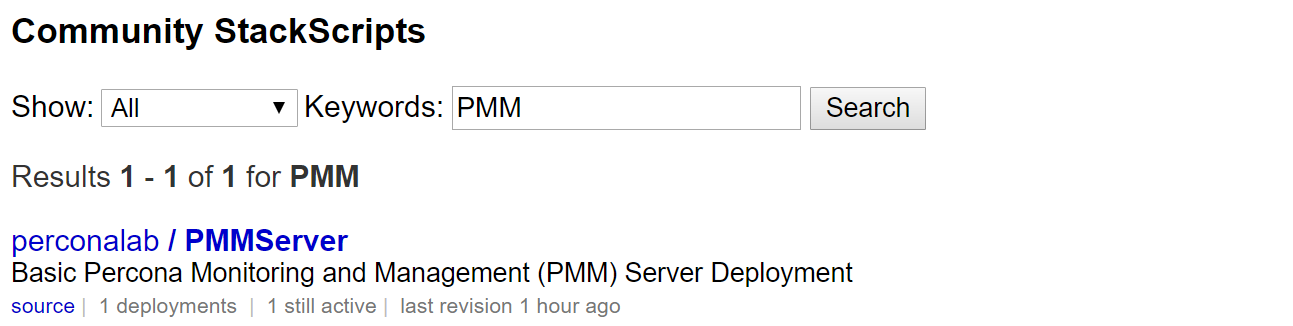
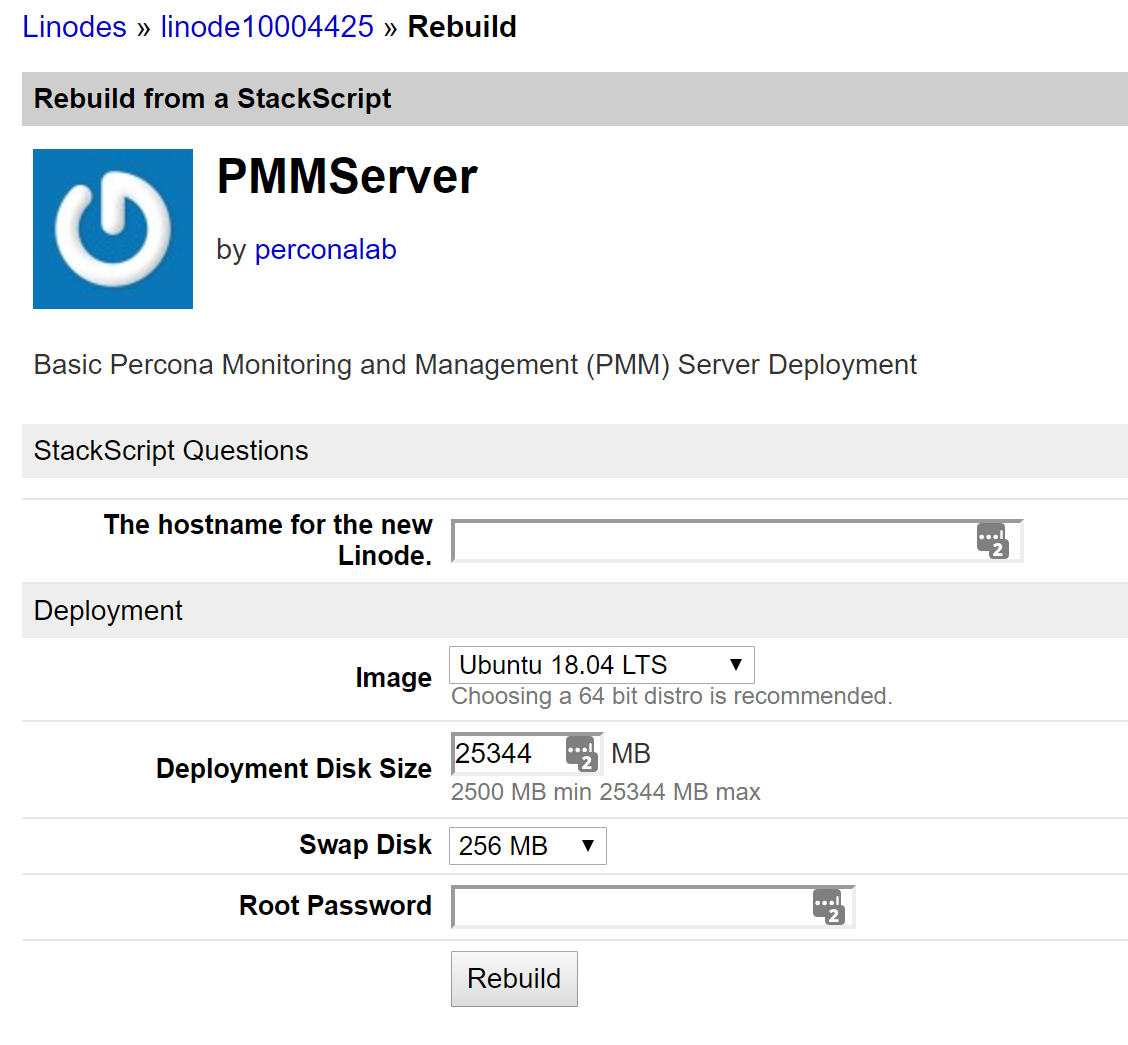
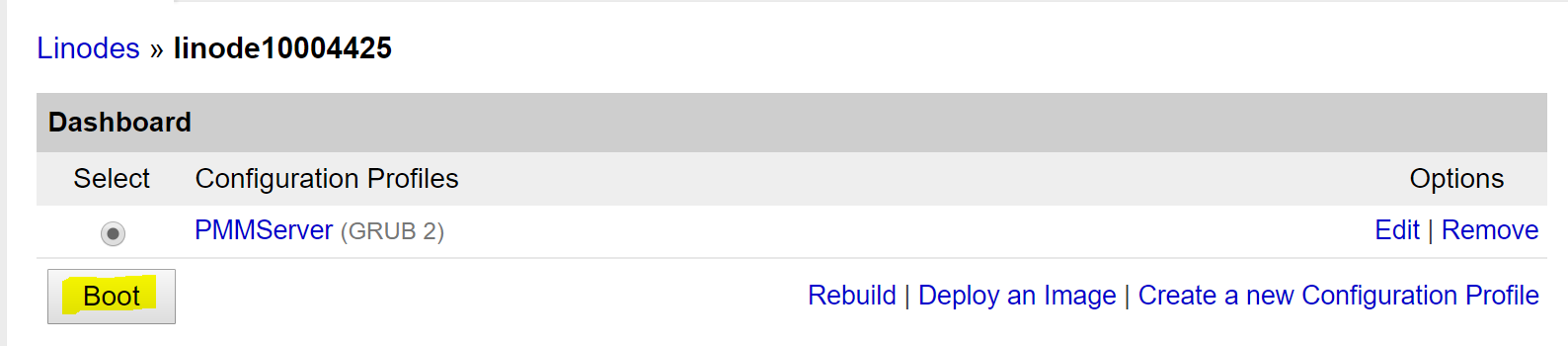
 This post is another in the series on Percona’s MongoDB 3.4 bundle release. This post is meant to walk a prospective user through the benefits of Percona Monitoring and Management (PMM), how it’s architected and the simple install process. By the end of this post, you should have a good idea of what PMM is, where it can add value in your environment and how you can get PMM going quickly.
This post is another in the series on Percona’s MongoDB 3.4 bundle release. This post is meant to walk a prospective user through the benefits of Percona Monitoring and Management (PMM), how it’s architected and the simple install process. By the end of this post, you should have a good idea of what PMM is, where it can add value in your environment and how you can get PMM going quickly.