
We have several PostgreSQL versions that support logical decoding to replicate data changes from a source database to a target database, which is a cool and very powerful tool that gives the option to replicate all the tables in a database, only one schema, a specific set of tables or even only some columns/rows, also is a helpful method for version upgrades since the target database can run on a different (minor or major) PostgreSQL version.
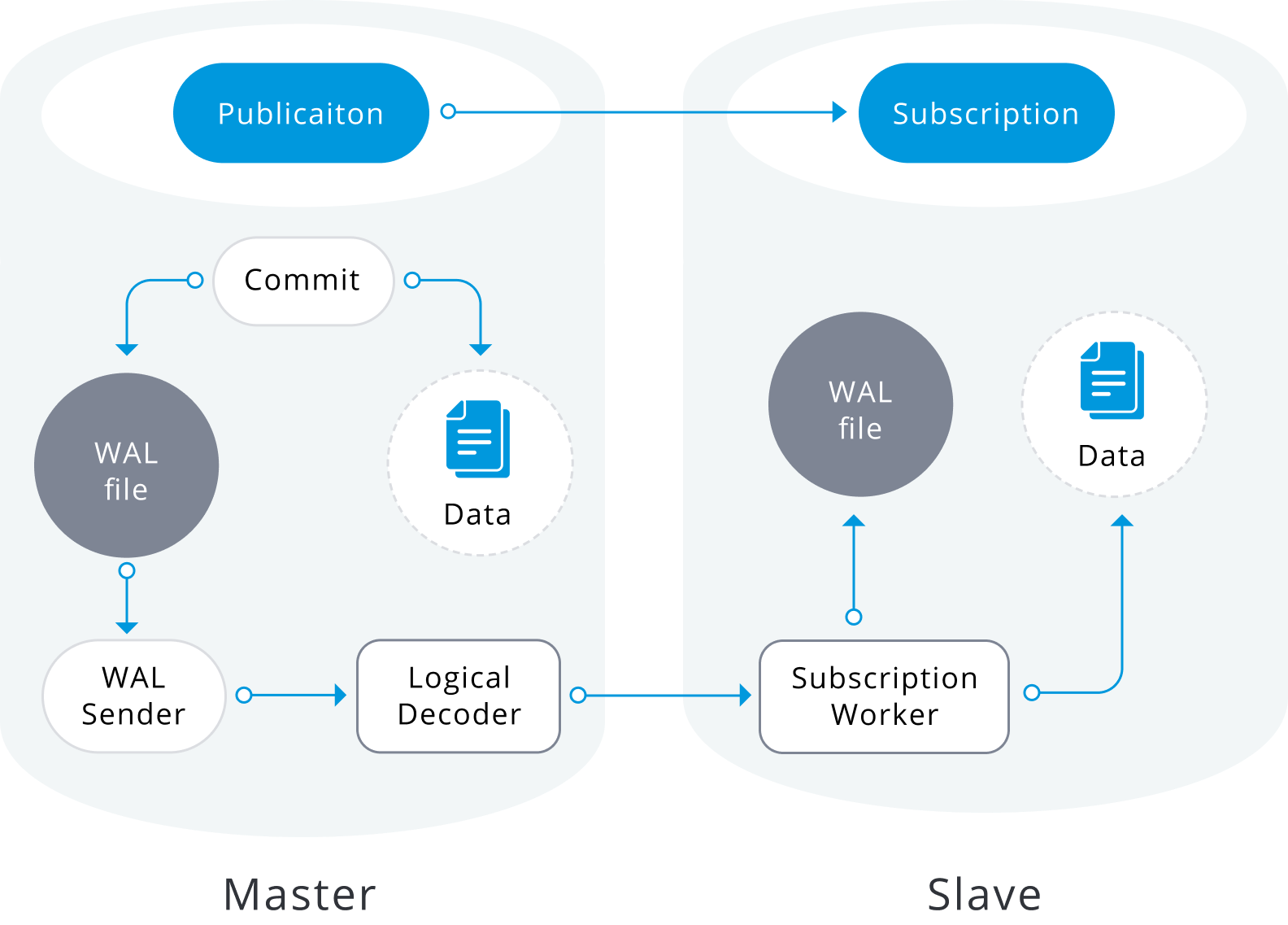
Image from: https://severalnines.com/sites/default/files/blog/node_5443/image2.png
There are some cases when the databases have been hosted in the AWS Relational Database Service (RDS) which is the fully auto-managed solution offered by Amazon Web Services, there is no secret that choosing this option for our database backend comes with a level of vendor lock-in, and even when RDS offers some build-in replica solutions such as Multi-AZ or read-replicas sometimes we can take advantage of the benefits from logical replication.
In this post I will describe the simplest and basic steps I used to implement this replica solution avoiding the initial copy data from the source database to the target, creating the target instance from an RDS snapshot. Certainly, you can take advantage of this when you work with a big/huge data set and the initial copy could lead to high timeframes or network saturation.
NOTE: The next steps were tested and used for a specific scenario and they are not intended to be an any-size solution, rather give some insight into how this can be made and most importantly, to stimulate your own creative thinking.
The Scenario
Service Considerations
In this exercise, I wanted to perform a version upgrade from PostgreSQL v11.9 to PostgreSQL v12.5, we can perform a direct upgrade using the build-in option RDS offers, but that requires a downtime window that can vary depending on some of the next:
- Is Multi-AZ enabled?
- Are the auto backups enabled?
- How transactional is the source database?
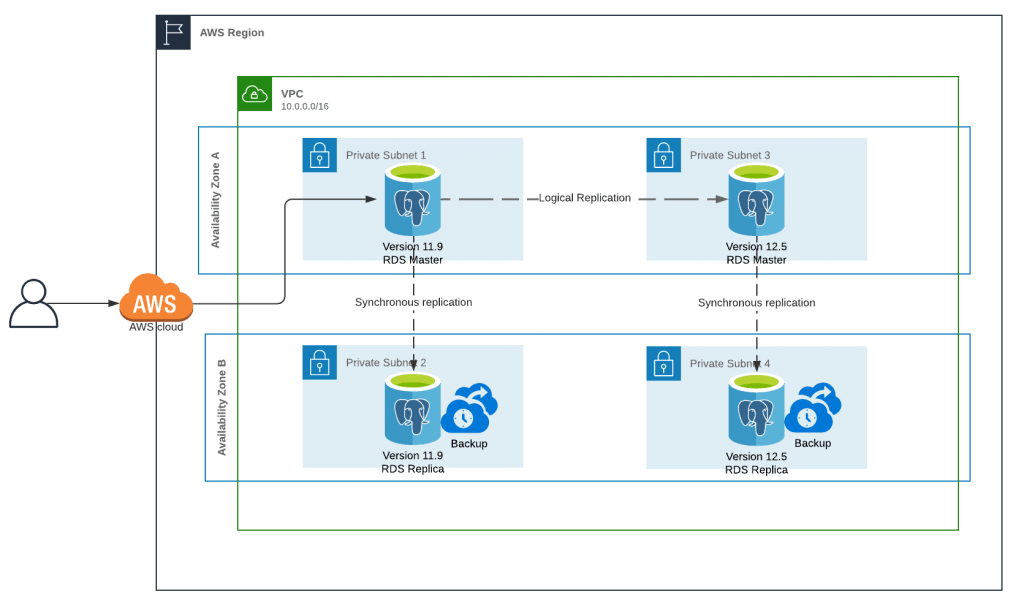
During the direct upgrade process, RDS takes a couple of new snapshots of the source instance, firstly at the beginning of the upgrade and finally when all the modifications are done, depending on how old is the previous backup and how many changes have been made on the datafiles the pre backup could take some time. Also, if the instance is Multi-AZ the process should upgrade both instances, which adds more time for the upgrade, during most of these actions the database remains inaccessible.
The next is a basic diagram of how an RDS Multi-AZ instance looks, all the client requests are sent to the master instance, while the replica is not accessible and some tasks like the backups are executed on it.

Therefore, I choose logical replication as the mechanism to achieve the objective, we can aim for a quicker switch-over if we create the new instance in the desired version and just replicate all the data changes, then we need a small downtime window just to move the traffic from the original instance to the upgraded new one.


Prerequisites
To be able to perform these actions we would need:
- An AWS user/access that can operate the DB instances, take DB snapshots and upgrade and restore them.
- The AWS user also should be able to describe and create DB PARAMETER GROUPS.
- A DB user with enough privileges to create the PUBLICATION on source and SUBSCRIPTION on target also is advisable to create a dedicated replication user with the minimum permissions.
The 1-2-3 Steps
Per the title of this post, the next is the list of steps to set up a PostgreSQL logical replication between a PostgreSQL v11.9 and a v12.5 using an RDS snapshot to initialize the target database.
- Verify the PostgreSQL parameters for logical replication
- Create the replication user and grant all the required privileges
- Create the PUBLICATION
- Create a REPLICATION SLOT
- Create a new RDS snapshot
- Upgrade the RDS snapshot to the target version
- Restore the upgraded RDS snapshot
- Get the LSN position
- Create the SUBSCRIPTION
- Advance the SUBSCRIPTION
- Enable the SUBSCRIPTION
Source Database Side
1. Verify the PostgreSQL parameters for logical replication
We require the next PostgreSQL parameters for this exercise
demodb=> select name,setting from pg_settings where name in (
'wal_level',
'track_commit_timestamp',
'max_worker_processes',
'max_replication_slots',
'max_wal_senders') ;
name | setting
------------------------+---------
max_replication_slots | 10
max_wal_senders | 10
max_worker_processes | 10
track_commit_timestamp | on
wal_level | logical
(5 rows)
NOTE: The parameter track_commit_timestamp can be optional since in some environments is not advisable for the related overhead, but it would help to track and resolve any conflict that may occur when the subscriptions are started.
2. Create the replication user and grant all the required privileges
demodb=> CREATE USER pgrepuser WITH password 'SECRET';
CREATE ROLE
demodb=> GRANT rds_replication TO pgrepuser;
GRANT ROLE
demodb=> GRANT SELECT ON ALL TABLES IN SCHEMA public TO pgrepuser;
GRANT
3. Create the PUBLICATION
demodb=> CREATE PUBLICATION pglogical_rep01 FOR ALL TABLES;
CREATE PUBLICATION
4. Create a REPLICATION SLOT
demodb=> SELECT pg_create_logical_replication_slot('pglogical_rep01', 'pgoutput');
pg_create_logical_replication_slot
------------------------------------
(pglogical_rep01,3C/74000060)
(1 row)
AWS RDS Steps
5. Create a new RDS snapshot
aws rds create-db-snapshot \
--db-instance-identifier demodb-postgres\
--db-snapshot-identifier demodb-postgres-to-125
6. Upgrade the RDS snapshot to the target version
aws rds modify-db-snapshot \
--db-snapshot-identifier demodb-postgres-to-125 \
--engine-version 12.5
7. Restore the upgraded RDS snapshot
Since we are moving from version 11.9 to 12.5 we may need to create a new DB parameter group if we are using some custom parameters.
From the instance describe we can verify the current parameter group
aws rds describe-db-instances \
--db-instance-identifier demodb-postgres \|
jq '.DBInstances | map({DBInstanceIdentifier: .DBInstanceIdentifier, DBParameterGroupName: .DBParameterGroups[0].DBParameterGroupName})'
[
{
"DBInstanceIdentifier": "demodb-postgres",
"DBParameterGroupName": "postgres11-logicalrep"
}
]
Then we can validate the custom parameters
aws rds describe-db-parameters \
--db-parameter-group-name postgres11-logicalrep \
--query "Parameters[*].[ParameterName,ParameterValue]" \
--source user --output text
track_commit_timestamp 1
We need to create a new parameter group in the target version
aws rds create-db-parameter-group \
--db-parameter-group-name postgres12-logicalrep \
--db-parameter-group-family postgres12
Finally, we need to modify the parameters we got before in the new parameter group
aws rds modify-db-parameter-group \
--db-parameter-group-name postgres12-logicalrep \
--parameters "ParameterName='track_commit_timestamp',ParameterValue=1,ApplyMethod=immediate"
Now we can use the new parameter group to restore the upgraded snapshot
aws rds restore-db-instance-from-db-snapshot \
--db-instance-identifier demodb-postgres-125 \
--db-snapshot-identifier demodb-postgres-to-125 \
--db-parameter-group-name postgres12-logicalrep
8. Get the LSN position from the target instance log
To list all the database logs for the new DB instance
aws rds describe-db-log-files \
--db-instance-identifier demodb-postgres-125
We should pick the latest database log
aws rds download-db-log-file-portion \
--db-instance-identifier demodb-postgres-125 \
--log-file-name "error/postgresql.log.2021-03-23-18"
From the retrieved log portion we need to find the value after for the log entry redo done at:
...
2021-03-23 18:19:58 UTC::@:[5212]:LOG: redo done at 3E/50000D08
...
Target Database Side
9. Create SUBSCRIPTION
demodb=> CREATE SUBSCRIPTION pglogical_sub01 CONNECTION 'host=demodb-postgres.xxxx.us-east-1.rds.amazonaws.com port=5432 dbname=demodb user=pgrepuser password=SECRET' PUBLICATION pglogical_rep01
WITH (
copy_data = false,
create_slot = false,
enabled = false,
connect = true,
slot_name = 'pglogical_rep01'
);
CREATE SUBSCRIPTION
10. Advance the SUBSCRIPTION
We need to get the subscription id
demodb=> SELECT 'pg_'||oid::text AS "external_id"
FROM pg_subscription
WHERE subname = 'pglogical_sub01';
external_id
-------------
pg_73750
(2 rows)
Now advance the subscription to the LSN we got in step 8
demodb=> SELECT pg_replication_origin_advance('pg_73750', '3E/50000D08') ;
pg_replication_origin_advance
-------------------------------
(1 row)
11. Enable the SUBSCRIPTION
demodb=> ALTER SUBSCRIPTION pglogical_sub01 ENABLE;
ALTER SUBSCRIPTION
Once we are done with all the steps the data changes should flow from the source database to the target, we can check the status at the pg_stat_replication view.
Conclusion
Choosing DBaaS from cloud vendors bring some advantages and can speed up some implementations, but they come with some costs, and not all the available tools or solutions fits all the requirements, that is why always is advisable to try some different approaches and think out of the box, technology can go so far as our imagination.

 A recommendation we often give to our customers is along the lines of “archive old data” to reduce your database size. There is a tradeoff between keeping all our data online and archiving part of it to cold storage.
A recommendation we often give to our customers is along the lines of “archive old data” to reduce your database size. There is a tradeoff between keeping all our data online and archiving part of it to cold storage.




 As mentioned in the
As mentioned in the 
 In a previous blog post on
In a previous blog post on 


 Now that Database-as-a-service (DBaaS) is in high demand, there is one question regarding AWS services that cannot always be answered easily : When should I use Aurora and when RDS MySQL?
Now that Database-as-a-service (DBaaS) is in high demand, there is one question regarding AWS services that cannot always be answered easily : When should I use Aurora and when RDS MySQL?









