
 If you often deploy services in the cloud, you certainly, at least once, forgot to stop a test instance. I am like you and I forgot my share of these. Another mistake I do once in a while is to provision a bigger instance than needed, just in case, and forget to downsize it. While this is true for compute instances, it is especially true for database instances. Over time, this situation ends up adding a cost premium. In this post, we’ll discuss a solution to mitigate these extra costs, the use of the RDS Aurora Serverless service.
If you often deploy services in the cloud, you certainly, at least once, forgot to stop a test instance. I am like you and I forgot my share of these. Another mistake I do once in a while is to provision a bigger instance than needed, just in case, and forget to downsize it. While this is true for compute instances, it is especially true for database instances. Over time, this situation ends up adding a cost premium. In this post, we’ll discuss a solution to mitigate these extra costs, the use of the RDS Aurora Serverless service.
What is Amazon Aurora Serverless?
Since last spring, Amazon unveiled a new database related product: RDS Aurora Serverless. The aim of this new product is to simplify the management around Aurora clusters. It brings a likely benefit for the end users, better control over cost. Here are some of the benefits we can expect from this product:
- Automatic scaling up
- Automatic scaling down
- Automatic shutdown after a period of inactivity
- Automatic startup
The database is constantly monitored and if the load grows beyond a given threshold, a bigger Aurora instance is added to the cluster, the connections are moved and the old instance is dropped. The opposite steps happen when a low load is detected. Also, if the database is completely inactive for some time, it is automatically stopped and restarted when needed. The RDS Aurora Serverless cluster type is available for MySQL (5.6 and 5.7) and PostgreSQL (10.12).
Architecture
The RDS Aurora Serverless architecture is similar to the regular RDS Aurora one. There are three main components; a proxy layer handling the endpoints, the servers processing the queries, and the storage. The proxy layer and the storage are about the same. As the name implies, what is dynamic with the Aurora Serverless type are the servers.
There are not many details available as to how things are actually implemented but likely but the proxy layer is able to transfer a connection from one server to another when there is a scale up or down event. Essentially, we can assume that when the cluster is modified, the steps are the following:
- A new Aurora server instance is created with the new size
- The new instance is added to the Aurora cluster
- The writer role is transferred to the new instance
- The existing connections are moved
- The old instance is removed
How To Configure It
The configuration of an RDS Aurora Serverless cluster is very similar to a regular Aurora cluster, there are just a few additional steps. First, of course, you need to choose the serverless type:

And then you have to specify the limits of your cluster in “Capacity”. The capacity unit is ACU which stands for Aurora Capacity Unit. I couldn’t find the exact meaning for the ACU, the documentation has: “Each ACU is a combination of processing and memory capacity.”. An ACU seems to provide about 2GB of RAM and the range of possible values is 1 to 256. You set the minimum and maximum ACU you want for the cluster in the following dialog box:

The last step is to specify the inactivity timeout after which the database is paused:

How It Works
Startup
If the Aurora Serverless cluster has no running server instances, an attempt to connect to the database will trigger the creation of a new instance. This process takes some time. I used a simple script to measure the connection time after an inactivity timeout and found the following statistics:
Min = 31s Max = 54s average = 42s StdDev = 7.1s Count = 17
You’ll need to make sure the application is aware of a new connection, as the database can take close to a minute to complete. I got caught a few times with sysbench timing out after 30s. It is important to remember the initial capacity used is the same as the one when the Aurora Serverless instance stopped, unless you enabled the “Force scaling the capacity…” parameter in the configuration.
Pause
If an Aurora Serverless cluster is idle for more than its defined inactivity time, it will be automatically paused. The inactivity here is defined in terms of active connections, not queries. An idle connection doing nothing will prevent the Aurora Serverless instance from stopping. If you intend to use the automatic pause feature, I recommend setting the “wait_timeout” and “interactive_timeout” to values in line with the cluster inactivity time.
Scale Up
A process monitors the Aurora Serverless instance and if it sees a performance issue that could be solved by the use of a larger instance type, it triggers a scale up event. When there is an ongoing scale up (or down) event, you’ll see a process like this one in the MySQL process list:
call action start_seamless_scaling('AQEAAEgBh893wRScvsaFbDguqAqinNK7...
Bear in mind a scale up event can take some time, especially if the server is very busy. While doing some benchmarks, I witness more than 200s on a few occasions. The queries load is affected for a few seconds when the instances are swapped.
To illustrate the scale up behavior, I ran a modified sysbench benchmark to force some CPU load. Here’s a 32 threads benchmarks scanning a table on an Aurora Serverless cluster having an initial capacity of 1.

The first scale up happened a little after 600s while the second one occurred around 1100s. The second event didn’t improve much the load but that is likely an artifact of the benchmark. It took a long time to increase the capacity from 1 to 2, it could be related to the high CPU usage on the instance. There is usually a small disruption of the query load when the instances are swapped but nothing too bad.
Scale Down
While scale up events happen when needed, scale down events are throttled to about once per 5 minutes except if the previous scaling event was a “scale up”, then the delay is 15 minutes.
Pros and Cons of Aurora Serverless
The RDS Aurora Serverless offering is very compelling for many use cases. It reduces the cost and simplifies the management. However, you must accept the inherent limitations like the long start up time when the instance was on pause and the small hiccups when the capacity is modified. If you cannot cope with the start up time, you can just configure the instance so it doesn’t pause, it will scale down to a capacity of 1 which seems to map to a t3.small instance type.
Of course, such an architecture imposes some drawbacks. Here’s a list of a few cons:
- As we have seen, the scale up time is affected by the database load
- Failover can also take more time than normally expected, especially if the ACU value is high
- You are limited to one node although, at an ACU of 256, it means a db.r4.16xlarge
- No public IP but you can set up a Data API
- The application must be robust in the way it deals with database connections because of possible delays and reconnections
Cost Savings
The cost of an RDS Aurora cluster has three components: the instance costs, the IO costs, and the storage costs. The Aurora Serverless offering affects only the instance costs. The cost is a flat rate per capacity unit per hour. Like for the normal instances, the costs are region-dependent. The lowest is found in the us-east at $0.06 USD per Capacity unit per hour.
If we consider a database used by web developers during the day and which can be paused out of the normal work hours and during the weekends, the saving can be above $240/month if the daily average capacity is only eight hours.

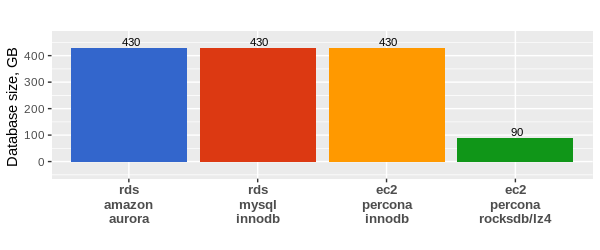






































 HA can be added to a basic Aurora implementation by adding an Aurora Replica. We increase our HA level by adding Aurora Replicas within the same AZ. If desired, the Aurora Replicas can be used to also service some of the read traffic for the Aurora Cluster. This configuration cannot be said to provide DR because there are no database nodes outside the single datacenter or AZ. If that datacenter were to fail, then database availability would be lost until it was manually restored in another datacenter (AZ). It’s important to note that while Aurora has a lot of built-in automation, you will only benefit from that automation if your base configuration facilitates a path for the automation to follow. If you have a single-AZ base deployment, then you will not have the benefit of automated Multi-AZ availability. However, as in the previous case, durability remains the same. Again, durability is a characteristic of the storage layer. The image below is a view of what this configuration looks like in the AWS Console. Note that the Writer and Reader are in the same AZ.
HA can be added to a basic Aurora implementation by adding an Aurora Replica. We increase our HA level by adding Aurora Replicas within the same AZ. If desired, the Aurora Replicas can be used to also service some of the read traffic for the Aurora Cluster. This configuration cannot be said to provide DR because there are no database nodes outside the single datacenter or AZ. If that datacenter were to fail, then database availability would be lost until it was manually restored in another datacenter (AZ). It’s important to note that while Aurora has a lot of built-in automation, you will only benefit from that automation if your base configuration facilitates a path for the automation to follow. If you have a single-AZ base deployment, then you will not have the benefit of automated Multi-AZ availability. However, as in the previous case, durability remains the same. Again, durability is a characteristic of the storage layer. The image below is a view of what this configuration looks like in the AWS Console. Note that the Writer and Reader are in the same AZ.
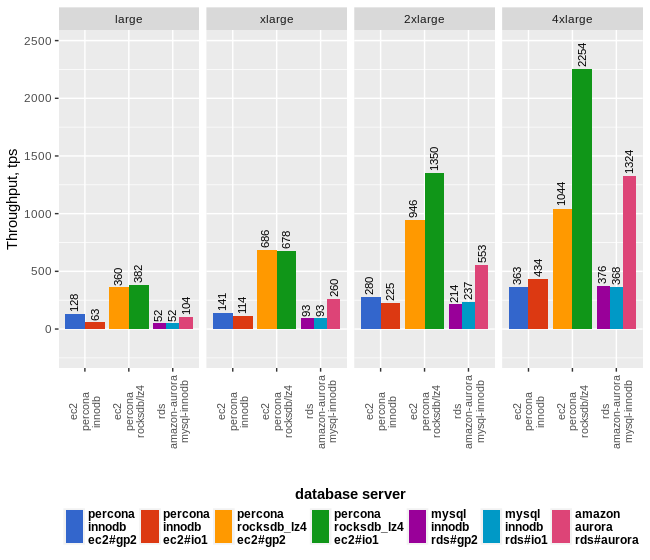
 Building on our previous example, we can increase our level of HA and add partial DR capabilities to the configuration by adding more Aurora Replicas. At this point we will add one additional replica in the same AZ, bringing the local AZ replica count to three database instances. We will also add one replica in each of the two remaining regional AZs. Aurora provides the option to configure automated failover priority for the Aurora Replicas. Choosing your failover priority is best defined by the individual business needs. That said, one way to define the priority might be to set the first failover to the local-AZ replicas, and subsequent failover priority to the replicas in the other AZs. It is important to remember that AZs within a region are physical datacenters located within the same metro area. This configuration will provide protection for a disaster localized to the datacenter. It will not, however, provide protection for a city-wide disaster. The image below is a view of what this configuration looks like in the AWS Console. Note that we now have two Readers in the same AZ as the Writer and two Readers in two other AZs.
Building on our previous example, we can increase our level of HA and add partial DR capabilities to the configuration by adding more Aurora Replicas. At this point we will add one additional replica in the same AZ, bringing the local AZ replica count to three database instances. We will also add one replica in each of the two remaining regional AZs. Aurora provides the option to configure automated failover priority for the Aurora Replicas. Choosing your failover priority is best defined by the individual business needs. That said, one way to define the priority might be to set the first failover to the local-AZ replicas, and subsequent failover priority to the replicas in the other AZs. It is important to remember that AZs within a region are physical datacenters located within the same metro area. This configuration will provide protection for a disaster localized to the datacenter. It will not, however, provide protection for a city-wide disaster. The image below is a view of what this configuration looks like in the AWS Console. Note that we now have two Readers in the same AZ as the Writer and two Readers in two other AZs.
 One of the many announcements to come out of re:Invent 2018 is a product called Aurora Global Database. This is Aurora’s implementation of cross-region physical replication. Amazon’s published details on the solution indicate that it is storage level replication implemented on dedicated cross-region infrastructure with sub-second latency. In general terms, the idea behind a cross-region architecture is that the second region could be an exact duplicate of the primary region. This means that the primary region can have up to 15 Aurora Replicas and the secondary region can also have up to 15 Aurora Replicas. There is one database instance in the secondary region in the role of writer for that region. This instance can be configured to take over as the master for both regions in the case of a regional failure. In this scenario the secondary region becomes primary, and the writer in that region becomes the primary database writer. This configuration provides protection in the case of a regional disaster. It’s going to take some time to test this, but at the moment this architecture appears to provide the most comprehensive combination of Durability, HA, and DR. The trade-offs have yet to be thoroughly explored.
One of the many announcements to come out of re:Invent 2018 is a product called Aurora Global Database. This is Aurora’s implementation of cross-region physical replication. Amazon’s published details on the solution indicate that it is storage level replication implemented on dedicated cross-region infrastructure with sub-second latency. In general terms, the idea behind a cross-region architecture is that the second region could be an exact duplicate of the primary region. This means that the primary region can have up to 15 Aurora Replicas and the secondary region can also have up to 15 Aurora Replicas. There is one database instance in the secondary region in the role of writer for that region. This instance can be configured to take over as the master for both regions in the case of a regional failure. In this scenario the secondary region becomes primary, and the writer in that region becomes the primary database writer. This configuration provides protection in the case of a regional disaster. It’s going to take some time to test this, but at the moment this architecture appears to provide the most comprehensive combination of Durability, HA, and DR. The trade-offs have yet to be thoroughly explored.
