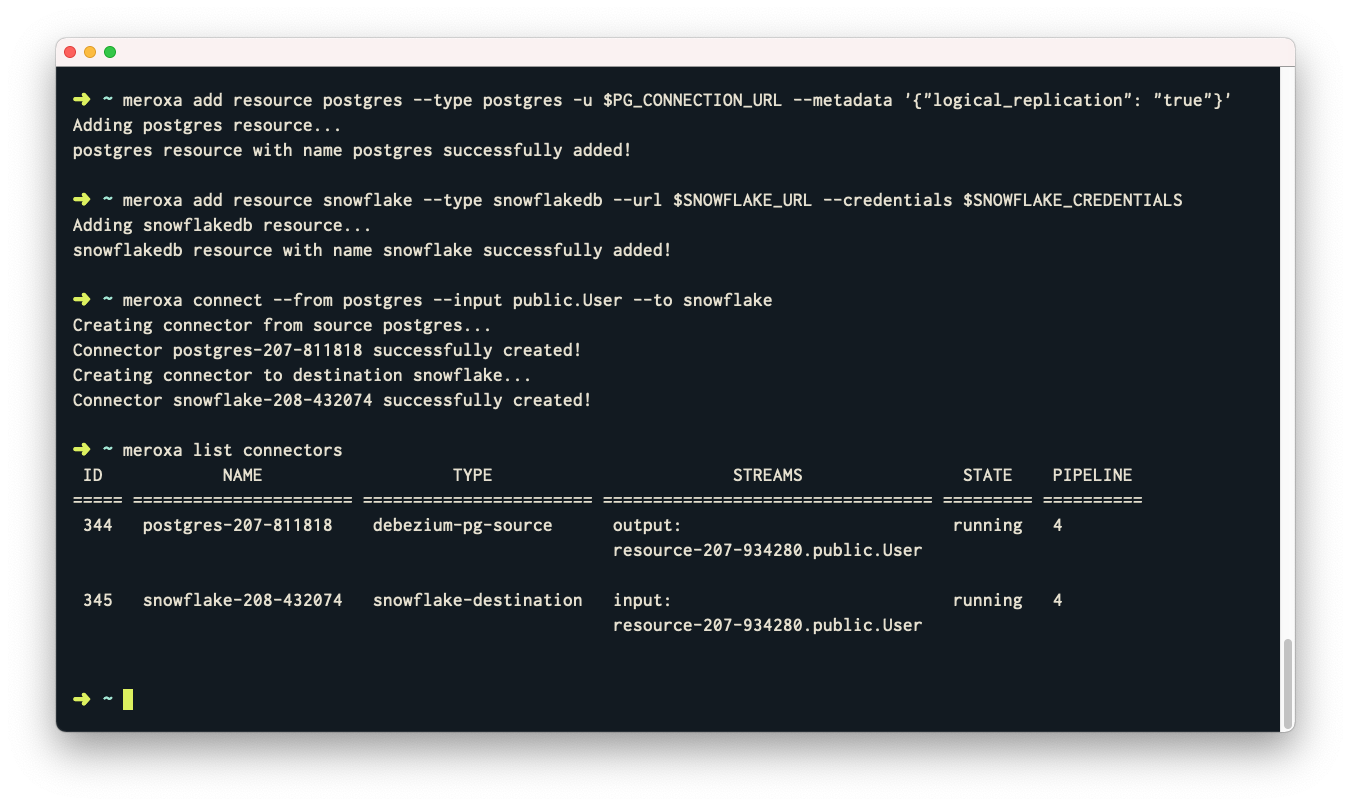
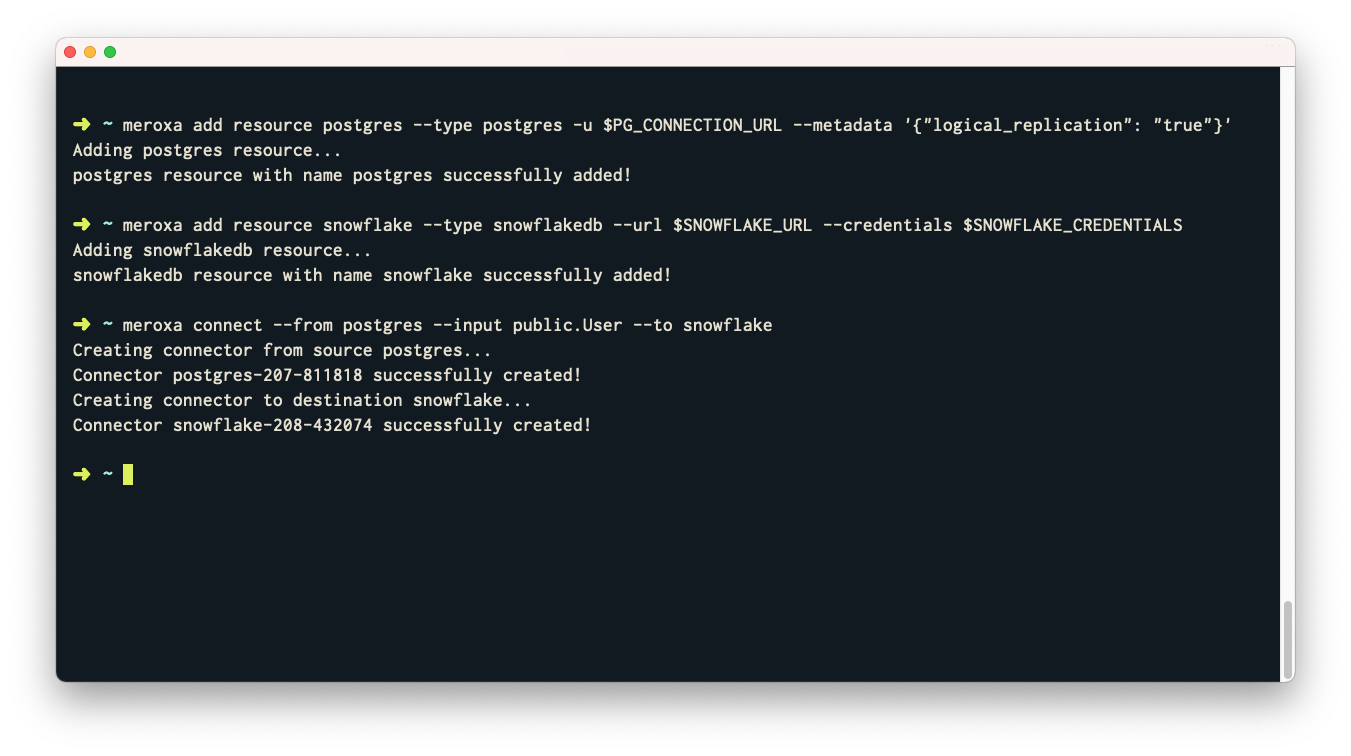
In this blog post, we will discuss how can we migrate from a replica set to sharded cluster.
In this blog post, we will discuss how can we migrate from a replica set to sharded cluster.
Before moving to migration let me briefly explain Replication and Sharding and why do we need to shard a replica Set.
Replication: It creates additional copies of data and allows for automatic failover to another node in case Primary went down. It also helps to scale our reads if the application is fine to read data that may not be the latest.
Sharding: It allows horizontal scaling of data writes by allowing data partition in multiple servers by using a shard key. Here, we should understand that a shard key is very important to distribute the data evenly across multiple servers.
Why Do We Need a Sharded Cluster?
We need sharding due to the below reasons:
- By adding shards, we can reduce the number of operations each shard manages.
- It increases the Read/Write capacity by distributing the Reads/Writes across multiple servers.
- It also gives high availability as we deploy the replicas for the shards, config servers, and multiple MongoS.
Sharded cluster will include two more components which are Config Servers and Query routers i.e. MongoS.
Config Servers: It keeps metadata for the sharded cluster. The metadata comprises a list of chunks on each shard and the ranges that define the chunks. The metadata indicates the state of all the data and its components within the cluster.
Query Routers(MongoS): It caches metadata and uses it to route the read or write operations to the respective shards. It also updates the cache when there are any metadata changes for the sharded cluster like Splitting of chunks or shard addition etc.
Note: Before starting the migration process it’s recommended that you perform a full backup (if you don’t have one already).
The Procedure of Migration:
- Initiate at least a three-member replica set for the Config Server ( another member can be included as a hidden node for the backup purpose).
- Perform necessary OS, H/W, and disk-level tuning as per the existing Replica set.
- Setup the appropriate clusterRole for the Config servers in the mongod config file.
- Create at least two more nodes for the Query routers ( MongoS )
- Set appropriate configDB parameters in the mongos config file.
- Repeat step 2 from above to tune as per the existing replica set.
- Apply proper SELinux policies on all the newly configured nodes of Config server and MongoS.
- Add clusterRole parameter into existing replica set nodes in a rolling fashion.
- Copy all the users from the replica set to any MongoS.
- Connect to any MongoS and add the existing replica set as Shard.
Note: Do not enable sharding on any database until the shard key is finalized. If it’s finalized then we can enable the sharding.
Detailed Migration Plan:
Here, we are assuming that a Replica set has three nodes (1 primary, and 2 secondaries)
- Create three servers to initiate a 3-member replica set for the Config Servers.
Perform necessary OS, H/W, and disk-level tuning. To know more about it, please visit our blog on Tuning Linux for MongoDB.
- Install the same version of Percona Server for MongoDB as the existing replica set from here.
- In the config file of the config server mongod, add the parameter clusterRole: configsvr and port: 27019 to start it as config server on port 27019.
- If SELinux policy is enabled then set the necessary SELinux policy for dbPath, keyFile, and logs as below.
sudo semanage fcontext -a -t mongod_var_lib_t '/dbPath/mongod.*' sudo chcon -Rv -u system_u -t mongod_var_lib_t '/dbPath/mongod' sudo restorecon -R -v '/dbPath/mongod' sudo semanage fcontext -a -t mongod_log_t '/logPath/log.*' sudo chcon -Rv -u system_u -t mongod_log_t '/logPath/log' sudo restorecon -R -v '/logPath/log' sudo semanage port -a -t mongod_port_t -p tcp 27019
Start all the Config server mongod instances and connect to any one of them. Create a temporary user on it and initiate the replica set.
> use admin
> rs.initiate()
> db.createUser( { user: "tempUser", pwd: "<password>", roles:[{role: "root" , db:"admin"}]})
Create a role anyResource with action anyAction as well and assign it to “tempUser“.
>db.getSiblingDB("admin").createRole({ "role": "pbmAnyAction",
"privileges": [
{ "resource": { "anyResource": true },
"actions": [ "anyAction" ]
}
],
"roles": []
});
>
>db.grantRolesToUser( "tempUser", [{role: "pbmAnyAction", db: "admin"}] )
> rs.add("config_host[2-3]:27019")
Now our Config server replica set is ready, let’s move to deploying Query routers i.e. MongoS.
- Create two instances for the MongoS and tune the OS, H/W, and disk. To do it follow our blog Tuning Linux for MongoDB or point 1 from the above Detailed migration.
- In mongos config file, adjust the configDB parameter and include only non-hidden nodes of Config servers ( In this blog post, we have not mentioned starting hidden config servers).
- Apply SELinux policies if it’s enabled, then follow step 4 and keep the same keyFile and start the MongoS on port 27017.
- Add the below parameter in mongod.conf on the Replica set nodes. Make sure the services are restarted in a rolling fashion i.e. start with the Secondaries then step down the existing Primary and restart it with port 27018.
clusterRole: shardsvr
Login to any MongoS and authenticate using “tempUser” and add the existing replica set as a shard.
> sh.addShard( "replicaSetName/<URI of the replica set>") //Provide URI of the replica set
Verify it with:
> sh.status() or db.getSiblingDB("config")['shards'].find()
Connect to the Primary of the replica set and copy all the users and roles. To authenticate/authorize mention the replica set user.
> var mongos = new Mongo("mongodb://put MongoS URI string here/admin?authSource=admin") //Provide the URI of the MongoS with tempUser for authentication/authorization.
>db.getSiblingDB("admin").system.roles.find().forEach(function(d) {
mongos.getDB('admin').getCollection('system.roles').insert(d)});
>db.getSiblingDB("admin").system.users.find().forEach(function(d) { mongos.getDB('admin').getCollection('system.users').insert(d)});
- Connect to any MongoS and verify copied users on it.
- Shard the database if shardKey is finalized (In this post, we are not sharing this information as it’s related to migration of Replica set to Sharded cluster only).
Shard the database:
>sh.enableSharding("<db>")
Shard the collection with hash-based shard key:
>sh.shardCollection("<db>.<coll1>", { <shard key field> : "hashed" } )
Shard the collection with range based shard key:
sh.shardCollection("<db>.<coll1>", { <shard key field> : 1, ... } )
Conclusion
Migration of a MongoDB replica set to a sharded cluster is very important to scale horizontally, increase the read/write operations, and also reduce the operations each shard manages.
We encourage you to try our products like Percona Server for MongoDB, Percona Backup for MongoDB, or Percona Operator for MongoDB. You can also visit our site to know “Why MongoDB Runs Better with Percona”.

 O
O