With a special focus on Percona Operator for MySQL
Overview
HAProxy, ProxySQL, MySQL Router (AKA MySQL Proxy); in the last few years, I had to answer multiple times on what proxy to use and in what scenario. When designing an architecture, many components need to be considered before deciding on the best solution.
When deciding what to pick, there are many things to consider, like where the proxy needs to be, if it “just” needs to redirect the connections, or if more features need to be in, like caching and filtering, or if it needs to be integrated with some MySQL embedded automation.
Given that, there never was a single straight answer. Instead, an analysis needs to be done. Only after a better understanding of the environment, the needs, and the evolution that the platform needs to achieve is it possible to decide what will be the better choice.
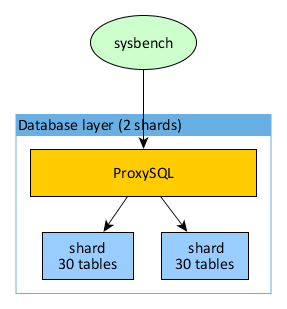
However, recently we have seen an increase in the usage of MySQL on Kubernetes, especially with the adoption of Percona Operator for MySQL. In this case, we have a quite well-defined scenario that can resemble the image below:

In this scenario, the proxies must sit inside Pods, balancing the incoming traffic from the Service LoadBalancer connecting with the active data nodes.
Their role is merely to be sure that any incoming connection is redirected to nodes that can serve them, which includes having a separation between Read/Write and Read Only traffic, a separation that can be achieved, at the service level, with automatic recognition or with two separate entry points.
In this scenario, it is also crucial to be efficient in resource utilization and scaling with frugality. In this context, features like filtering, firewalling, or caching are redundant and may consume resources that could be allocated to scaling. Those are also features that will work better outside the K8s/Operator cluster, given the closer to the application they are located, the better they will serve.
About that, we must always remember the concept that each K8s/Operator cluster needs to be seen as a single service, not as a real cluster. In short, each cluster is, in reality, a single database with high availability and other functionalities built in.
Anyhow, we are here to talk about Proxies. Once we have defined that we have one clear mandate in mind, we need to identify which product allows our K8s/Operator solution to:
- Scale at the maximum the number of incoming connections
- Serve the request with the higher efficiency
- Consume as fewer resources as possible
The environment
To identify the above points, I have simulated a possible K8s/Operator environment, creating:
- One powerful application node, where I run sysbench read-only tests, scaling from two to 4096 threads. (Type c5.4xlarge)
- Three mid-data nodes with several gigabytes of data in with MySQL and Group Replication (Type m5.xlarge)
- One proxy node running on a resource-limited box (Type t2.micro)
The tests
We will have very simple test cases. The first one has the scope to define the baseline, identifying the moment when we will have the first level of saturation due to the number of connections. In this case, we will increase the number of connections and keep a low number of operations.
The second test will define how well the increasing load is served inside the previously identified range.
For documentation, the sysbench commands are:
Test1
sysbench ./src/lua/windmills/oltp_read.lua --db-driver=mysql --tables=200 --table_size=1000000 --rand-type=zipfian --rand-zipfian-exp=0 --skip_trx=true --report-interval=1 --mysql-ignore-errors=all --mysql_storage_engine=innodb --auto_inc=off --histogram --stats_format=csv --db-ps-mode=disable --point-selects=50 --reconnect=10 --range-selects=true –rate=100 --threads=<#Threads from 2 to 4096> --time=1200 run
Test2
sysbench ./src/lua/windmills/oltp_read.lua --mysql-host=<host> --mysql-port=<port> --mysql-user=<user> --mysql-password=<pw> --mysql-db=<schema> --db-driver=mysql --tables=200 --table_size=1000000 --rand-type=zipfian --rand-zipfian-exp=0 --skip_trx=true --report-interval=1 --mysql-ignore-errors=all --mysql_storage_engine=innodb --auto_inc=off --histogram --table_name=<tablename> --stats_format=csv --db-ps-mode=disable --point-selects=50 --reconnect=10 --range-selects=true --threads=<#Threads from 2 to 4096> --time=1200 run
Results
Test 1
As indicated here, I was looking to identify when the first Proxy will reach a dimension that would not be manageable. The load is all in creating and serving the connections, while the number of operations is capped at 100.

As you can see, and as I was expecting, the three Proxies were behaving more or less the same, serving the same number of operations (they were capped, so why not) until they weren’t.
MySQL router, after the 2048 connection, could not serve anything more.
NOTE: MySQL Router actually stopped working at 1024 threads, but using version 8.0.32, I enabled the feature: connection_sharing. That allows it to go a bit further.
Let us take a look also the latency:

Here the situation starts to be a little bit more complicated. MySQL Router is the one that has the higher latency no matter what. However, HAProxy and ProxySQL have interesting behavior. HAProxy performs better with a low number of connections, while ProxySQL performs better when a high number of connections is in place.
This is due to the multiplexing and the very efficient way ProxySQL uses to deal with high load.
Everything has a cost:

HAProxy is definitely using fewer user CPU resources than ProxySQL or MySQL Router …

.. we can also notice that HAProxy barely reaches, on average, the 1.5 CPU load while ProxySQL is at 2.50 and MySQL Router around 2.
To be honest, I was expecting something like this, given ProxySQL’s need to handle the connections and the other basic routing. What was instead a surprise was MySQL Router, why does it have a higher load?
Brief summary
This test highlights that HAProxy and ProxySQL can reach a level of connection higher than the slowest runner in the game (MySQL Router). It is also clear that traffic is better served under a high number of connections by ProxySQL, but it requires more resources.
Test 2
When the going gets tough, the tough get going
Let’s remove the –rate limitation and see what will happen.

The scenario with load changes drastically. We can see how HAProxy can serve the connection and allow the execution of more operations for the whole test. ProxySQL is immediately after it and behaves quite well, up to 128 threads, then it just collapses.
MySQL Router never takes off; it always stays below the 1k reads/second, while HAProxy served 8.2k and ProxySQL 6.6k.

Looking at the latency, we can see that HAProxy gradually increased as expected, while ProxySQL and MySQL Router just went up from the 256 threads on.
To observe that both ProxySQL and MySQL Router could not complete the tests with 4096 threads.

Why? HAProxy always stays below 50% CPU, no matter the increasing number of threads/connections, scaling the load very efficiently. MySQL router was almost immediately reaching the saturation point, being affected by the number of threads/connections and the number of operations. That was unexpected, given we do not have a level 7 capability in MySQL Router.
Finally, ProxySQL, which was working fine up to a certain limit, reached saturation point and could not serve the load. I am saying load because ProxySQL is a level 7 proxy and is aware of the content of the load. Given that, on top of multiplexing, additional resource consumption was expected.

Here we just have a clear confirmation of what was already said above, with 100% CPU utilization reached by MySQL Router with just 16 threads, and ProxySQL way after at 256 threads.
Brief summary
HAProxy comes up as the champion in this test; there is no doubt that it could scale the increasing load in connection without being affected significantly by the load generated by the requests. The lower consumption in resources also indicates the possible space for even more scaling.
ProxySQL was penalized by the limited resources, but this was the game, we had to get the most out of the few available. This test indicates that it is not optimal to use ProxySQL inside the Operator; it is a wrong choice if low resource and scalability are a must.
MySQL Router was never in the game. Unless a serious refactoring, MySQL Router is designed for very limited scalability, as such, the only way to adopt it is to have many of them at the application node level. Utilizing it close to the data nodes in a centralized position is a mistake.
Conclusions
I started showing an image of how the MySQL service is organized and want to close by showing the variation that, for me, is the one to be considered the default approach:

This highlights that we must always choose the right tool for the job.
The Proxy in architectures involving MySQL/Percona Server for MySQL/Percona XtraDB Cluster is a crucial element for the scalability of the cluster, no matter if using K8s or not. Choosing the one that serves us better is important, which can sometimes be ProxySQL over HAProxy.
However, when talking about K8s and Operators, we must recognize the need to optimize the resources usage for the specific service. In that context, there is no discussion about it, HAProxy is the best solution and the one we should go to.
My final observation is about MySQL Router (aka MySQL Proxy).
Unless there is a significant refactoring of the product, at the moment, it is not even close to what the other two can do. From the tests done so far, it requires a complete reshaping, starting to identify why it is so subject to the load coming from the query more than the load coming from the connections.
Great MySQL to everyone.
References

 Our recent
Our recent 




 Please join Percona’s Architect, Tibi Köröcz as he presents
Please join Percona’s Architect, Tibi Köröcz as he presents 

 Please join Percona’s Architect, Tibi Köröcz as he presents
Please join Percona’s Architect, Tibi Köröcz as he presents