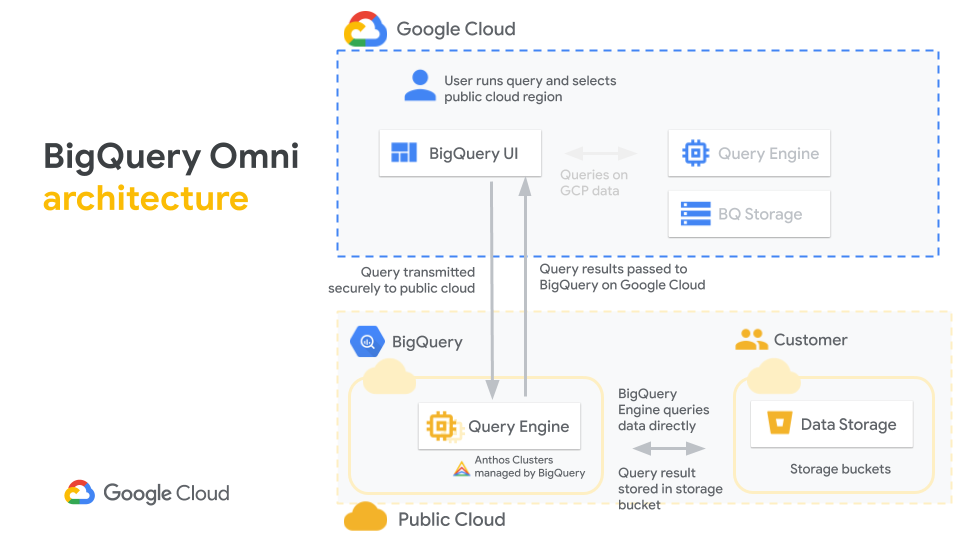
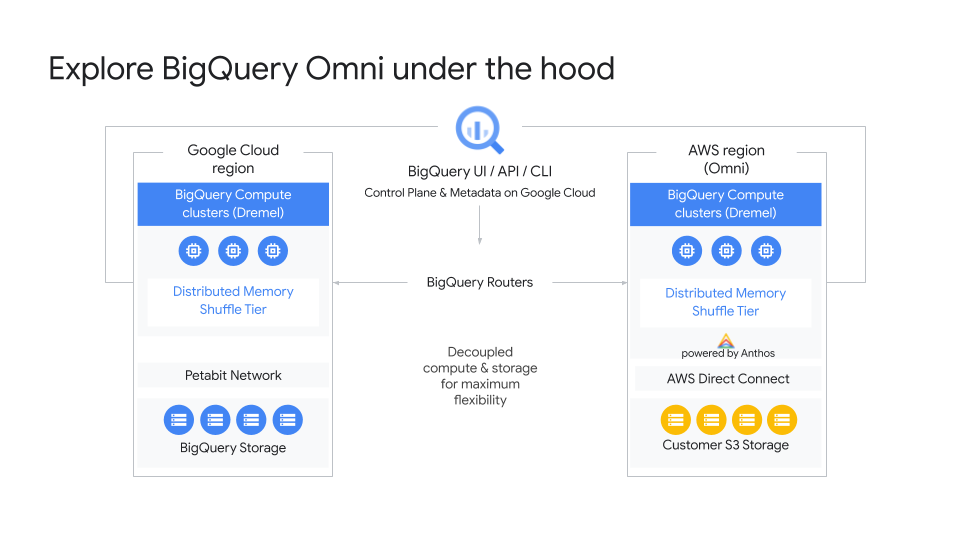
When the inventor of AWS Lambda, Tim Wagner, and the former head of blockchain at AWS, Shruthi Rao, co-found a startup, it’s probably worth paying attention. Vendia, as the new venture is called, combines the best of serverless and blockchain to help build a truly multicloud serverless platform for better data and code sharing.
Today, the Vendia team announced that it has raised a $5.1 million seed funding round, led by Neotribe’s Swaroop ‘Kittu’ Kolluri. Correlation Ventures, WestWave Capital, HWVP, Firebolt Ventures, Floodgate and Future\Perfect Ventures also participated in this oversubscribed round.

Image Credits: Vendia
Seeing Wagner at the helm of a blockchain-centric startup isn’t exactly a surprise. After building Lambda at AWS, he spent some time as VP of engineering at Coinbase, where he left about a year ago to build Vendia.
“One day, Coinbase approached me and said, ‘Hey, maybe we could do for the financial system what you’ve been doing over there for the cloud system,’” he told me. “And so I got interested in that. We had some conversations. I ended up going to Coinbase and spent a little over a year there as the VP of Engineering, helping them to set the stage for some of that platform work and tripling the size of the team.” He noted that Coinbase may be one of the few companies where distributed ledgers are actually mission-critical to their business, yet even Coinbase had a hard time scaling its Ethereum fleet, for example, and there was no cloud-based service available to help it do so.

Tim Wagner, Vendia co-founder and CEO. Image Credits: Vendia
“The thing that came to me as I was working there was why don’t we bring these two things together? Nobody’s thinking about how would you build a distributed ledger or blockchain as if it were a cloud service, with all the things that we’ve learned over the course of the last 10 years building out the public cloud and learning how to do it at scale,” he said.
Wagner then joined forces with Rao, who spent a lot of time in her role at AWS talking to blockchain customers. One thing she noticed was that while it makes a lot of sense to use blockchain to establish trust in a public setting, that’s really not an issue for enterprise.
“After the 500th customer, it started to make sense,” she said. “These customers had made quite a bit of investment in IoT and edge devices. They were gathering massive amounts of data. They also made investments on the other side, with AI and ML and analytics. And they said, ‘Well, there’s a lot of data and I want to push all of this data through these intelligent systems. I need a mechanism to get this data.’” But the majority of that data often comes from third-party services. At the same time, most blockchain proof of concepts weren’t moving into any real production usage because the process was often far too complex, especially enterprises that maybe wanted to connect their systems to those of their partners.

Shruthi Rao, Vendia co-founder and CBO. Image Credits: Vendia
“We are asking these partners to spin up Kubernetes clusters and install blockchain nodes. Why is that? That’s because for blockchain to bring trust into a system to ensure trust, you have to own your own data. And to own your own data, you need your own node. So we’re solving fundamentally the wrong problem,” she explained.
The first product Vendia is bringing to market is Vendia Share, a way for businesses to share data with partners (and across clouds) in real-time, all without giving up control over that data. As Wagner noted, businesses often want to share large data sets but they also want to ensure they can control who has access to that data. For those users, Vendia is essentially a virtual data lake with provenance tracking and tamper-proofing built in.
The company, which mostly raised this round after the coronavirus pandemic took hold in the U.S., is already working with a couple of design partners in multiple industries to test out its ideas, and plans to use the new funding to expand its engineering team to build out its tools.
“At Neotribe Ventures, we invest in breakthrough technologies that stretch the imagination and partner with companies that have category creation potential built upon a deep-tech platform,” said Neotribe founder and managing director Kolluri. “When we heard the Vendia story, it was a no-brainer for us. The size of the market for multiparty, multicloud data and code aggregation is enormous and only grows larger as companies capture every last bit of data. Vendia’s serverless-based technology offers benefits such as ease of experimentation, no operational heavy lifting and a pay-as-you-go pricing model, making it both very consumable and highly disruptive. Given both Tim and Shruthi’s backgrounds, we know we’ve found an ideal ‘Founder fit’ to solve this problem! We are very excited to be the lead investors and be a part of their journey.”